
Causal clustering, developed based on the Raft protocol, enables support for large clusters and different cluster topologies for data center and cloud. It includes built-in load balancing which is handled by Neo4j Bolt drivers. Neo4j database also supports new cluster-aware sessions, managed by the Bolt drivers, that help with the infrastructure concerns for developers.
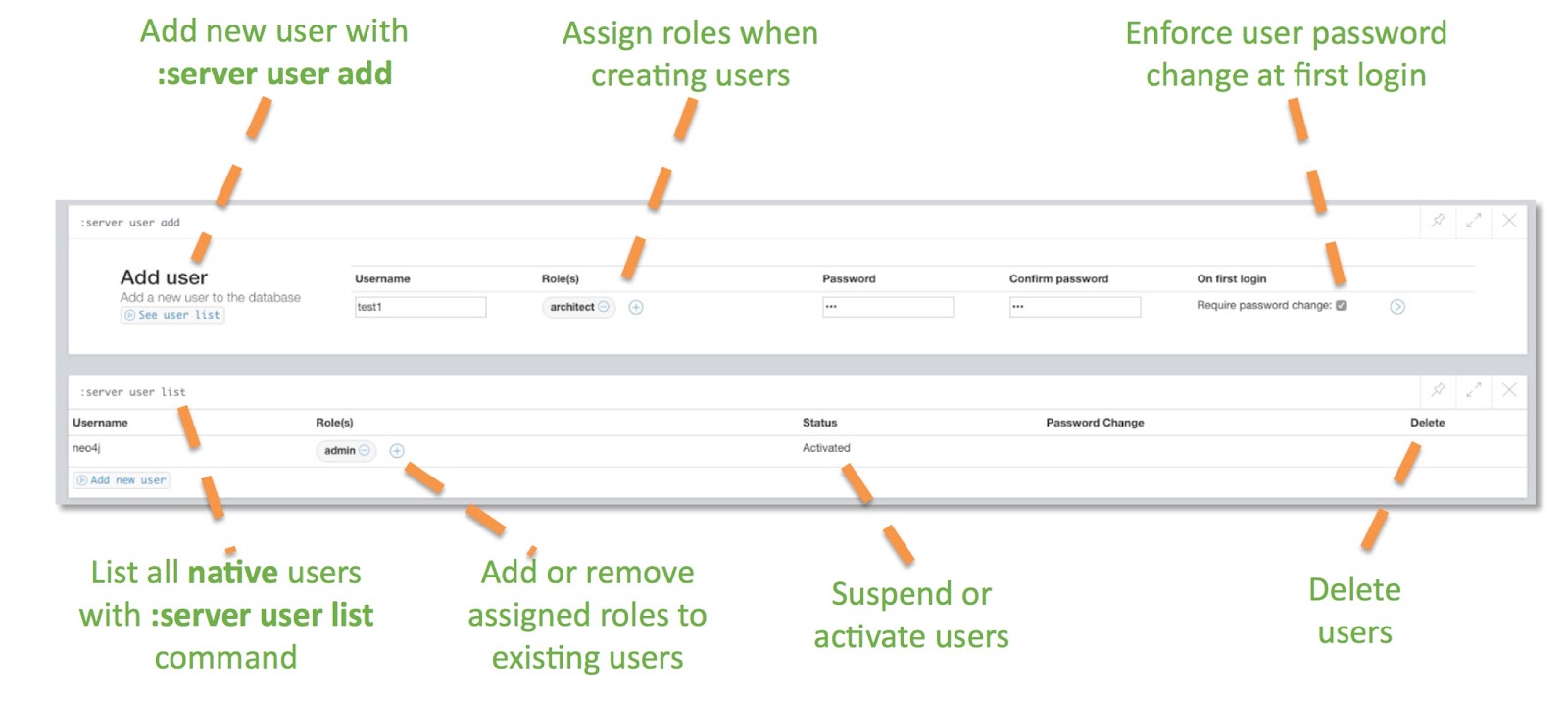
Security enhancements include the features like multiple users, role-based access control (comes with four predefined graph-global data-access roles: reader, publisher, architect and admin), query & security event logging, list and terminate running queries, and fine-grained access control.
Other features in the latest version include database kernel improvements with more efficient space management and a Schema Viewer that displays the graph model at the current point in time.
InfoQ spoke with Michael Hunger from Neo4j team about the new release.
InfoQ: Can you discuss the new causal clustering feature in Neo4j 3.1 release and how it’s different than the traditional clustering techniques?
Michael Hunger: The new Causal Clustering is a completely new architecture and approach to clustering a transactional database. It is independent of the previous implementation Neo4j High Availability (HA) and addresses several issues of the former approach.
The main focus is to provide total data safety, i.e. transactionally safe operations and availability. The approach builds on Neo4j’s historically strong transaction support via the Raft protocol and an asynchronous replication protocol to extend guarantees about reading your own writes even in very large clusters.
Eventual consistency – the default choice for most NoSQL databases – does not support this model. Despite read-your-own-writes being similar to how a standard Von Neumann computer works and so a familiar model, most NoSQL databases force developers to battle with consistency again and again in their applications.
For any clustered database, especially ones with eventual consistency, the “read your own writes” problem is tricky to solve, especially for user-facing applications. Usually it is handled with sticky sessions that redirect subsequent reads to the server that was written to, which limits scalability.
Causal Clustering goes far beyond eventual consistency to provide the simplest but most profound of guarantees: What you write you can subsequently read, even when the cluster is large.






{kind=link}